

This article is more than
1 year old
OpenAI decided that siphoning up other people’s data isn’t cool… if they aren’t the one doing it.
Oh, the schadenfreude. All around the internet, people are gloating that mere months after trying to Jedi mind trick away a host of lawsuits claiming that OpenAI unfairly trains its AI models, such as ChatGPT, on newspapers’ content and authors’ books.
Chinese generative AI DeepSeek was kicking OpenAI’s ChatGPT ass when it came to headlines and downloads. DeepSeek became the most downloaded free app on the Apple App Store for a time earlier this week, days before DeepSeek unleashed the AI image generator Janus-Pro that took aim at OpenAI DALL-E’s unguarded face.
East meets West at the most elementary slapfight in Big Tech this year. Has DeepSeek been a naughty copycat, or is OpenAI just a sore loser? Find out at the flagpole at 3 o’clock after class.
LET’S DISTILL IT DOWN
“We know that groups in the PRC (People’s Republic of China) are actively working to use methods, including what’s known as distillation, to try to replicate advanced U.S. AI models,” an OpenAI spokesperson said to Inc. in a statement.
“We are aware of and reviewing indications that DeepSeek may have inappropriately distilled our models, and will share information as we know more. We take aggressive, proactive countermeasures to protect our technology and will continue working closely with the U.S. government to protect the most capable models being built here.”
And in speaking with Financial Times (watch out for that paywall), an OpenAI spokesperson said they may have evidence of distillation (there’s that word again) that seemed to be linked to DeepSeek, but again they didn’t elaborate or share that proof.
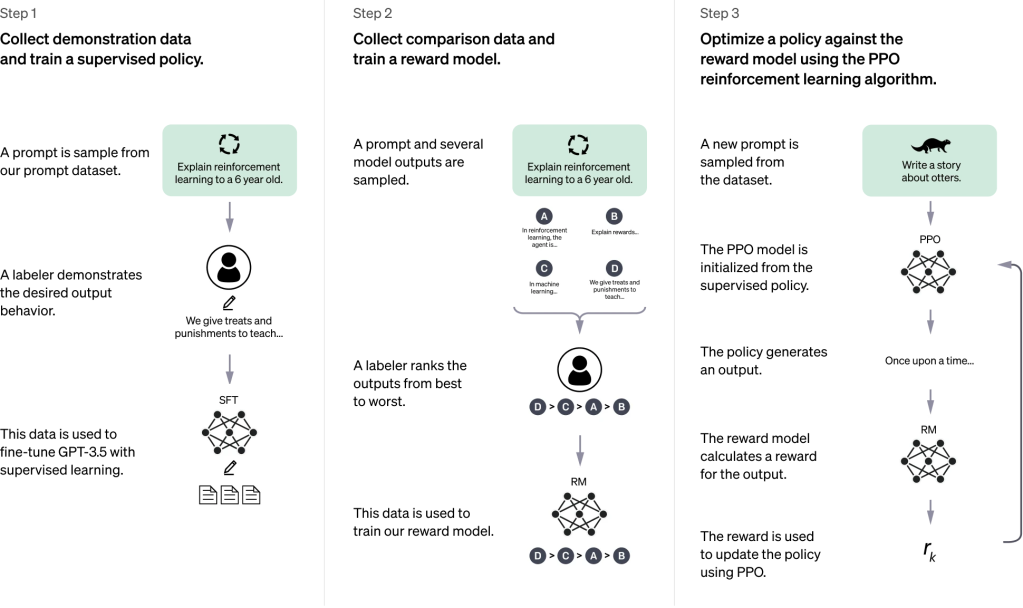
CHATGPT LEARNING MODEL – CREDIT: OPENAI
Distillation is a process by which an actor asks a deep neural network, such as ChatGPT, tons and tons of questions in order to collect its answers. It sucks the knowledge of the “teacher” model—the one being asked the questions—to the “student” model. It’s a large-scale knowledge transfer.
It isn’t illegal, as far as US law goes, but it does violate OpenAI’s terms of service, which were last updated on December 11, 2024. They state that those who use OpenAI services or products may not “automatically or programmatically extract data or output” or “use output to develop models that compete with OpenAI.”
We’re eager to see how this plays out, especially since it’s a case of “he said, she said” at the moment. Show your cards, OpenAI. If it turns out there is credible evidence that DeepSeek violated OpenAI’s terms of service, we may as well turn the drama knob up to 11.




